By late 2025, "we're piloting an AI assistant" is a sentence you can hear in almost any boardroom.
The numbers back it up:
- A recent McKinsey survey finds almost all respondents say their organizations are using AI somewhere, and over two-thirds use it in multiple functions—yet only about one-third say they are scaling AI across the enterprise, and just 39% report any measurable EBIT impact from AI at all.
- Summaries of Stanford's AI Index 2025 report that 78% of organizations used AI in 2024, up from 55% in 2023, and over 70% used generative AI for at least one business function.
- Deloitte's "State of Generative AI in the Enterprise" notes that organizations are investing heavily, but sustainable ROI tends to come from a small number of well-governed, embedded use cases, not from generic chatbots floating above the business.
So adoption is high, impact is… mixed.
This guide focuses on how to build enterprise AI assistants that actually work in this 2025 environment: technically, operationally, and in terms of governance. Product names aside, these are the patterns that keep showing up in successful deployments.
What an "Enterprise AI Assistant" Really Is
An enterprise AI assistant is not "ChatGPT, but with your logo."
It's a system that:
- Answers questions and completes tasks using your organization's data and workflows
- Respects access controls and governance
- Produces traceable, auditable outputs
- Integrates into existing tools (CRM, ticketing, mission-planning tools, productivity suites, etc.)
- Can trigger actions (with guardrails), not just generate text
The large language model (LLM) is one building block. The rest of the system—data pipelines, retrieval, tools, security, logging, evaluation—is where most of the engineering and risk lives.
Current Adoption and Impact: What the Data Says
A few high-level takeaways from major 2024–2025 reports:
- Adoption is mainstream, scaling is not. McKinsey's 2025 survey: nearly all organizations use AI, but nearly two-thirds say they haven't started scaling across the enterprise.
- Generative AI is in "at least one function" almost everywhere. Syntheses of the AI Index 2025 report: 71% of enterprises use generative AI for at least one business function.
- ROI is concentrated. Deloitte's case studies show faster ROI where generative AI is layered onto existing processes with centralized governance and clear KPIs, especially in content drafting, customer support, and internal knowledge retrieval.
The lesson: "We deployed a chatbot" is almost meaningless as a statement. The question is: for which workflows, with what guardrails, and measured how?
Core Architecture Patterns (2025 Edition)
Most robust enterprise assistants converge on a similar layered architecture:
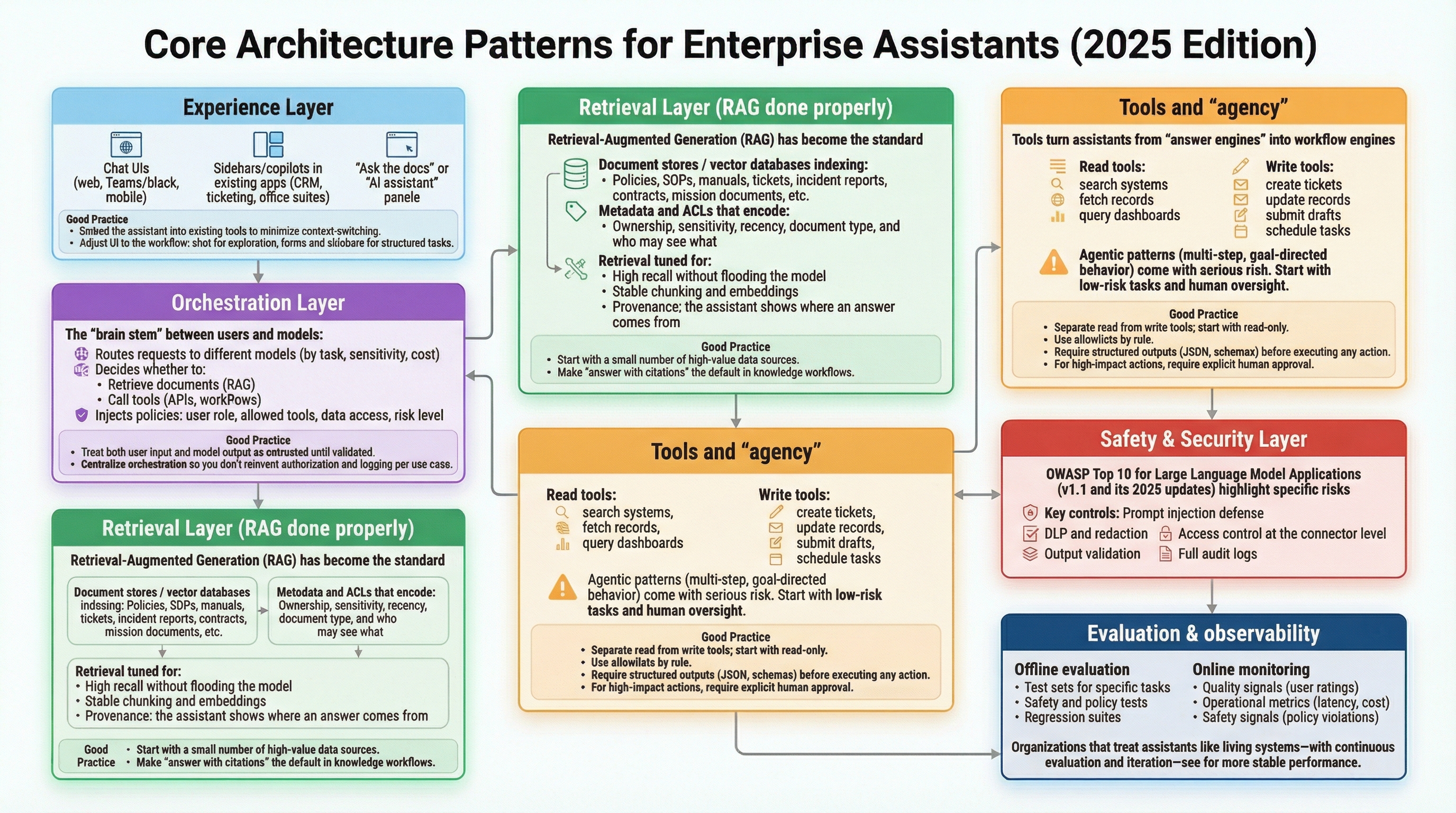
Experience Layer
Where users actually interact:
- Chat UIs (web, Teams/Slack, mobile)
- Sidebars/copilots in existing apps (CRM, ticketing, office suites)
- "Ask the docs" or "AI assistant" panels embedded in internal portals
Good practice:
- Embed the assistant into existing tools to minimize context-switching.
- Adjust UI to the workflow: chat for exploration, forms and sidebars for structured tasks.
Orchestration Layer
The "brain stem" between users and models:
- Routes requests to different models (by task, sensitivity, cost)
- Decides whether to:
- Retrieve documents (RAG)
- Call tools (APIs, workflows)
- Just answer from the model
- Injects policies: user role, allowed tools, data access, risk level
Good practice:
- Treat both user input and model output as untrusted until validated.
- Centralize orchestration so you don't reinvent authorization and logging per use case.
Retrieval Layer (RAG Done Properly)
Retrieval-Augmented Generation (RAG) has become the standard way to ground answers in enterprise data:
- Document stores / vector databases indexing:
- Policies, SOPs, manuals, tickets, incident reports, contracts, mission documents, etc.
- Metadata and ACLs that encode:
- Ownership, sensitivity, recency, document type, and who may see what
- Retrieval tuned for:
- High recall without flooding the model
- Stable chunking and embeddings
- Provenance: the assistant shows where an answer comes from
Good practice:
- Start with a small number of high-value data sources, not "everything we have."
- Maintain a clear "allowed corpus" for each assistant and role.
- Make "answer with citations" the default in knowledge workflows.
Tools and "Agency"
Tools turn assistants from "answer engines" into workflow engines:
- Read tools: search systems, fetch records, query dashboards.
- Write tools: create tickets, update records, submit drafts, schedule tasks.
Agentic patterns (multi-step, goal-directed behavior) are emerging, but they come with serious risk. Deloitte's 2025 commentary on agentic AI stresses starting with low-risk tasks, non-critical data, and human oversight while organizations build up data management and cybersecurity maturity.
Good practice:
- Separate read from write tools; start with read-only.
- Use allowlists by role ("finance analyst can draft, not approve, payments").
- Require structured outputs (JSON, schemas) before executing any action.
- For high-impact actions (money, HR, mission changes), require explicit human approval.
Safety & Security Layer
This is where 2025 looks very different from 2023.
The OWASP Top 10 for Large Language Model Applications (v1.1 and its 2025 updates) highlight specific risks for LLM apps: prompt injection, sensitive information disclosure, excessive agency, insecure output handling, supply-chain vulnerabilities, and more.
Key controls:
- Prompt injection defense: don't blindly trust retrieved content; treat external text as untrusted and constrain what tools can do.
- DLP and redaction: block secrets/PII from leaving your boundary; limit what's stored in logs.
- Output validation: especially for code, SQL, or configuration outputs—validate and sandbox before use.
- Access control at the connector level: apply existing permissions (SharePoint, Google Drive, line-of-business apps) all the way through retrieval and tools.
- Full audit logs: record who asked what, what data was touched, what tools were called, and what the final output was.
Evaluation & Observability
Without evaluation, you're flying blind.
Two complementary approaches:
Offline evaluation
- Test sets for specific tasks (Q&A, drafting, classification).
- Safety and policy tests (red-teaming scenarios).
- Regression suites to catch quality drift when you change prompts/models.
Online monitoring
- Quality signals (user ratings, corrections, escalation rate).
- Operational metrics (latency, cost, tool-call failure rates).
- Safety signals (policy violations, unusual tool usage, repeated refusals).
Organizations that treat assistants like living systems—with continuous evaluation and iteration—see far more stable performance than those that treat them like a one-time software deployment.
Data Security and Privacy Expectations
Enterprise assistants now sit on top of sensitive data and core systems. Typical expectations in 2025:
Data isolation
- Your data is not used to train shared models for other customers unless you explicitly opt in.
- Clear retention policies for prompts, outputs, and logs.
Fine-grained access control
- Per-user and per-group permissions applied consistently across connectors, retrieval, and tools.
- Row/field-level protections where applicable (e.g., masking certain fields in finance/health).
Data residency and sovereignty
- Control over data location (e.g., specific regions, sovereign cloud options).
- Clear mapping between assistant use cases and applicable regulations (HIPAA, PCI, CJIS, sector rules, etc.).
Secure software practices
- Secure software development patterns extended to LLM systems, as emphasized in NIST's 2024 guidance and the companion Secure Software Development Practices for generative AI.
Security teams increasingly treat "LLM + tools + data" as a first-class attack surface, not an experiment.
Governance and Regulation: The New Normal
Governance has caught up quickly over the last two years.
NIST AI RMF and the Generative AI Profile
NIST's AI Risk Management Framework (AI RMF 1.0) provides a general structure for managing AI risk. In 2024, NIST released AI 600-1, the Generative AI Profile, a companion document that identifies generative-specific risks (confabulation, prompt injection, deepfakes, etc.) and maps over 200 mitigation actions across the AI lifecycle.
For enterprise assistants, this translates into:
- Documented intended uses and out-of-scope uses
- Clear human-AI decision boundaries (what AI can propose vs decide)
- Lifecycle governance: design → development → deployment → monitoring → decommissioning
ISO/IEC 42001
ISO/IEC 42001 defines requirements for an AI management system—essentially ISO 27001 for AI governance. It gives organizations a certifiable way to show that they are managing AI risks systematically across processes and products.
For assistants, ISO 42001 alignment often means:
- Documented roles and responsibilities for AI use
- Policies covering data, models, monitoring, and incident response
- Integration with existing compliance and audit programs
EU AI Act and General-Purpose AI
The EU AI Act is now in its phased rollout:
- Prohibitions on certain "unacceptable risk" systems and AI literacy obligations took effect on February 2, 2025.
- Governance rules and obligations for general-purpose AI (GPAI) models, including those with systemic risk, began applying on August 2, 2025, with obligations for many high-risk uses coming into force by 2026.
Even if you are a deployer (not a model provider), this affects:
- Documentation and transparency expectations for assistants built on top of GPAI models
- Risk assessments and incident reporting
- Contract requirements with model providers
CEOs and tech groups have pushed back on complexity and timing, but the broad direction—risk-based regulation with stricter rules for high-risk and systemic-risk systems—is not going away.
Implementation Roadmap
A simplified, practical roadmap:
Phase 0 – Foundations
- Identify 2–5 high-value workflows (e.g., internal knowledge search, policy Q&A, case summarization, briefing drafting).
- Define data boundaries: what sources are in/out of scope.
- Set governance basics: owners, risk classification, logging and retention.
Phase 1 – Safe MVP
- Build a limited-scope assistant with:
- RAG over a constrained corpus
- Clear citations and refusal behavior
- Basic logging and RBAC
- Run offline tests (accuracy on representative questions, policy edge cases).
Phase 2 – Pilot in Production
- Release to a small, motivated user group.
- Track:
- Task completion time
- Escalation/override rates
- User satisfaction and trust
- Add low-risk tools (read-only APIs, draft generation) with human-in-the-loop.
Phase 3 – Broader Rollout
- Expand to more users and data sources.
- Introduce carefully scoped write tools, with approvals where needed.
- Integrate with your risk and compliance functions for regular review.
Phase 4 – Continuous Improvement
- Maintain evaluation suites and monitoring dashboards.
- Regularly review logs and incidents; update prompts, tools, and policies.
- Plan for model changes (new versions, new providers) with regression tests.
Common Pitfalls and How to Avoid Them
Some failure modes show up repeatedly:
"One big assistant for everything"
- Fix: start with domain-specific assistants tied to specific workflows and data.
No grounding, no citations
- Fix: make RAG + citations the default; configure the assistant to say "I don't know" when out of scope.
Excessive agency too early
- Fix: sequence it—read-only tools → draft-only tools → high-impact actions with approvals.
No measurement
- Fix: define task-level metrics (resolution time, throughput, quality), not just "number of chats."
Governance as an afterthought
- Fix: align early with security, legal, and risk; reference frameworks like NIST AI 600-1 and ISO 42001 to structure your controls.
Shadow AI
- Fix: provide a better sanctioned option—easy to access, permission-aware, and safe—so employees don't need to rely on unsanctioned consumer tools for sensitive work.
How This Connects to Tadata.ai and Second Wave Technologies
Everything above is intentionally vendor-neutral. These are the patterns that seem to work across industries, geographies, and regulatory regimes.
At Second Wave Technologies, our platform Tadata.ai is built specifically to implement this style of assistant:
- RAG-first, workflow-aware assistants that sit on top of complex document ecosystems (mission planning packs, compliance workbooks, policy sets, SOPs).
- A strong emphasis on permission-aware retrieval, tool gating, and logging, so assistants can operate inside high-stakes environments (like our DoD SBIR Phase I mission-planning work) without turning into uncontrolled agents.
- Deployment patterns tuned both for high-governance environments (defense, regulated industries) and resource-constrained teams (like the businesses and organizations we support through the Hawaii Wave incubator), using the same underlying architecture.
If you adopt nothing else from this article, adopt this: treat your assistant as a system, not a model. Whether you build it yourself or use something like Tadata.ai, the organizations that win in 2025 are the ones that combine:
- Solid architecture
- Serious governance
- Narrow, high-value workflows
…and then scale out from there, instead of trying to bolt "AI" on top of everything at once.
Need help planning your AI assistant implementation? Talk to our team about your specific needs.